
Building Blocks of Network Automation Architecture
Whilst building a Network Automation Platform, the following components need to start interacting with each other:
- User Interaction System
- Network and Storage Infrastructure
- Automation Engine
- Telemetry and Observability System
- Orchestration System
- Source of Truth
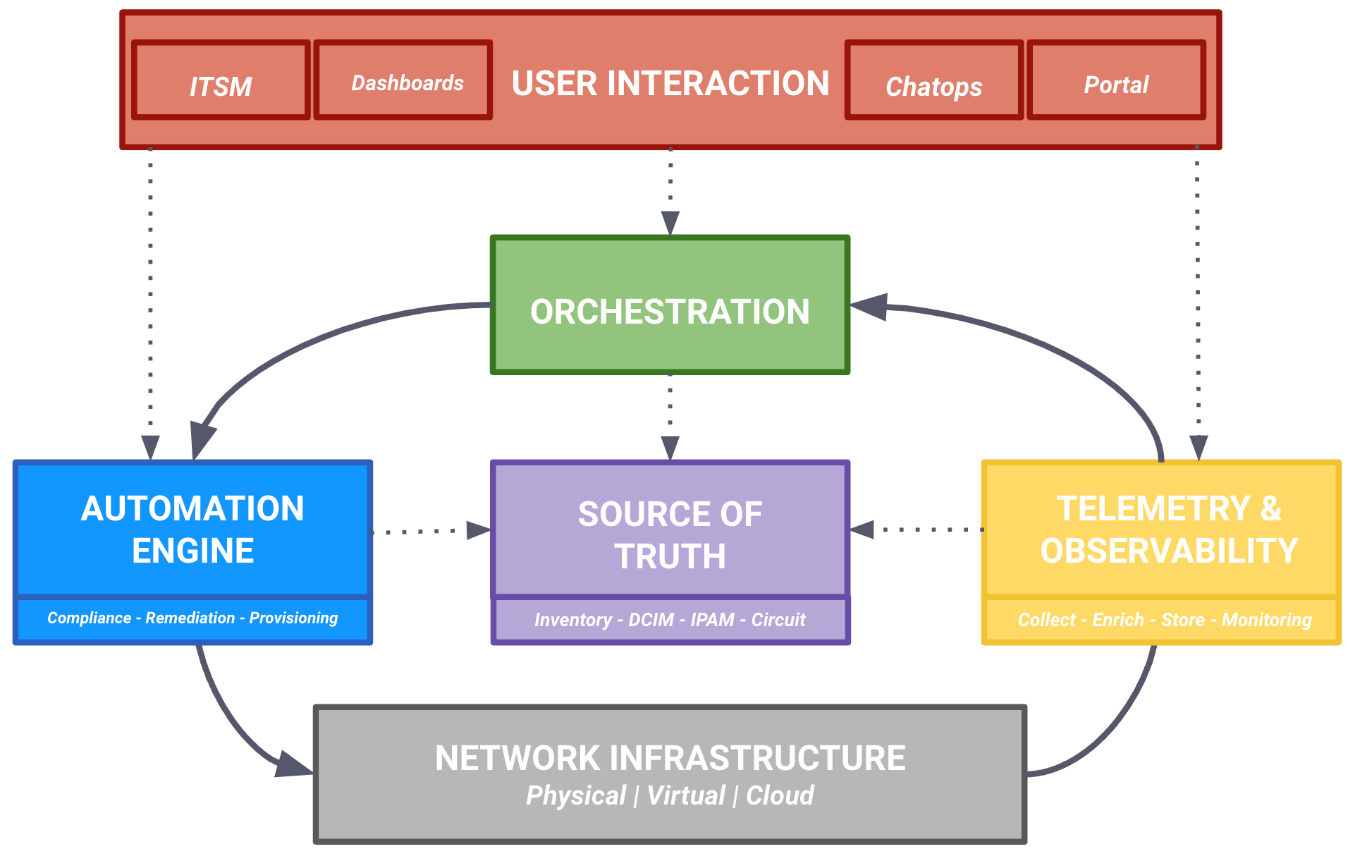
Figure 1: Network Automation Framework. Ref:networktocode.com
Let’s analyse the above components in more detail.
1) USER INTERACTION SYSTEM:

First, we have user interface systems. This is the entry point of humans into the platform. It comprises of tools such as ITSM, ticketing systems, and chat tools such as Slack.
A user interface could be a web page that presents data and reports and/or collects input data from the user. Frameworks such as Django and Flask together with react.js can provide you with a quick approach to developing enterprise-grade user interfaces. A tool like Grafana can also help you to quickly generate graphs and dashboards using network and other business systems data.
2) NETWORK AND STORAGE INFRASTRUCTURE:

Second, there’s network and storage infrastructure. Here are some of the common infrastructure that all organisations will need to start with. These include:
a: Linux servers:
A Linux server is a variant of the Linux operating system that is designed to handle more intense storage and operational needs of larger organizations and their software. Regardless of which automation you are developing, you are going to need a Linux server to run your automation tools. Redhat or Debian based linux distributions are a popular choice.
Linux servers are widely used today and considered amongst the most popular due to their stability, security, and flexibility, which outstrip standard Windows servers. They also give users significant flexibility in terms of set up, operation, and maintenance. Additionally, Linux Servers are generally lighter to run on both physical and cloud servers because they don’t require a graphics interface.
b: Storage space:
Second, let us explore storage space – Whether you are generating reports, versioning device configurations or collecting telemetry, you will need space to store all this information. The important thing here is to understand how much you need and whether a local array in the server, a cluster of servers, or offloading to the cloud is required.
The choice of database management system also matters. Time-series databases allow you to collect more data in terms of labels, this could be generic labels that we attach, or it can be very context aware metadata that is coming from the device itself, this enables you to do dynamic queries based off that metadata that can change while the data points are still intact.
3) Data communication and Security systems:
Finally, let us explore data communication systems – Communication systems interconnect the various components needed to sustain a network environment; for instance, it enables communication between user interface web pages, your linux servers and other network infrastructure.
Data communication systems have to be reliable, scalable and secure. Things like firewalls, encryption, authentication, proxies and role based access (RBAC) have to be carefully considered and be implemented in a transparent manner to the users and developers.
Which protocols and frameworks to use is also a key consideration here, some of the widely tried and tested protocols include MQTT, NETCONF, REST, RESTCONF, and gRPC. For the frameworks, we have Kafka, ZeroMQ, and RabbitMQ.
Please note the following points when choosing the kind of hardware to work with:
– Insist on hardware that has an API such as NETCONF and avoid relying on screen-scraping for automation.
– Choose hardware with good commit, rollback and diff mechanism
– Choose hardware with virtual images to enable testing and validating changes.
– For new projects, instead of core, aggregation and access topology, consider spine and leaf architectures – these are scalable to increase bandwidth for workloads, latency is much less, and more applicable to network automation.
4) DATA COLLECTION AND ANALYTICS SYSTEMS:

Data collection and analytics systems enable us to design, implement and maintain closed-loop feedback automation processes. In this case, data is both being fed into and extracted from the network infrastructure and related systems.
There are three main things to consider here:
a. Sources of Truth (SoT):
Automation is built around data, and a major automation challenge is determining what data to trust. This becomes even more important as you move from gathering data and creating reports to provisioning new devices or services and creating more advanced orchestration workflows.
Traditionally, the source of truth (SoT) has been copies of spreadsheets and notebooks distributed across multiple engineers, and the running configuration on the network infrastructure such as routers and switches. This is fundamentally wrong as the running config and varied copies of spreadsheets may not reflect what the intended state of the network ought to be.
The fundamentally right approach especially when it comes to architecting automation solutions, is to have authoritative sources of truth that are programmatically accessible and synchronized using API’s. Note that I said “sources of truth”, because realistically, we would have different sources of truth for different data domains.
For instance, we can have a tool like NetBox serving as the SoT for device inventory, IPAM as the source of truth for IP Addresses, DCIM as the SoT for data center infrastructure and ServiceNow or other CRM tool for tenant/client details such as addresses and contracts.
However, as the team from Network To Code advises; having many different sources of truth means each system in our network automation toolbox would potentially need to reference many different sources of truth to get the data needed to perform automation. A feasible work-around is to implement an aggregation layer between the sources of truth and the systems consuming their data.
The sources of truth can be aggregated and exposed using a single unified API. A single API layer makes it simpler to develop and monitor your platform, and easier to make changes to backend services as time goes by.
Your automation tools can then exchange data using the unified API to allow for a closed-loop pulling and pushing of validated data such as IP addresses, NTP servers, VLANs, configurations, device state metrics, IP addresses, device inventory information, policy rules, DNS servers, and more.
The single unified API can then implement a data translation layer which transforms the data coming from each source of truth into an abstracted data model. This data model intentionally strips away any features of the data or its structure which make it identifiable with any vendor or source implementation.
This allows the aggregation layer to interact with the various source of truth systems in a pluggable way, such that they can be swapped out at anytime. If you want to switch IPAM vendors, all you have to do is create an adaptor for the aggregator that understands what the data looks like coming out of the new IPAM.
Another thing, these sources of truth must be well governed, meaning that change controls are in place to protect against unauthorized changes. It should also be authoritative, assuring that no other data repositories can supersede it.
b. Data Formats and Models:
The journey towards closed-loop network automation requires that we have more machine to machine communication, we are trying to remove the human element out of the pipeline as much as possible. To do this, we need to choose data structures, formats and models that are easily comprehended by machines as opposed to humans.
A typical approach is to use JSON in northbound interfaces, especially when interacting with RESTful systems. NETCONF/XML is better suited to be used in the southbound interface. YAML can be used to handle infrastructure configurations for instance with Ansible. Google Protocol Buffers (aka “GPB” or “protobufs”) is a good fit for implementing streaming telemetry.
Data formats and models can also be used to implement data constraints for different sources of truth, for instance, a source of truth that is specifically tailored towards IPAM can put data constraints in place to avoid bad data specifically in the context of IPAM. Additionally, they also enable you to harness the power of templates in generating standardized configurations.
c. Monitoring, Streaming Telemetry, Alerting & Event Streams:
Next, when it comes to monitoring, streaming telemetry, alerting & event streams, we want to do more than just SNMP polling and traps, here, we are taking a step further to implement visualization using graphs, this empowers us to gain more insights into our network using the data in our systems. Tools like Prometheus, Grafana, Kibana, Kentik, and splunk come in handy, we can build customized operational dashboards using such tools.
5) CONFIGURATION MANAGEMENT SYSTEMS:

Network configuration management is the ongoing process of overseeing the setup and maintenance of all network devices, as well as the software and firmware installed on them. It encompasses the discovery of devices, the monitoring of device configuration and status, and the maintenance of inventory.
Automation of these processes is really key and could save on a lot of time. For instance, if you need to change the password of all cisco routers on a network, applying the change to every device individually would be a tedious process. This is where configuration templates come into play. You can centrally execute this operation to all the devices using Jinja templates.
A good network configuration management system will minimize configuration errors and optimize the security of your network. It should be able to carry out the following key tasks:
– Maintain a baseline of device configs
– Roll back changes to earlier configurations
– Archive git-style differences between various revisions of a configuration
– Poll network devices and create backups of configurations e.g to a Git repository or generic database
Tools like Git, Ansible, Python, Jinja, and SaltStack have a lot of application here.
6) ORCHESTRATION AND INTEGRATION SYSTEMS:
Orchestration and integration systems are the more advanced and mature parts of a network automation platform. Here you get to elevate what you’re doing with personal scripts, and have modular re-usable steps that can be built into complex workflows.
An orchestration system is responsible to execute your distributed, isolated and idempotent automated workflows in a particular sequence and manner to achieve a specific outcome.
As an example, an end to end system can have mechanisms to store and run Ansible playbooks, we can have CI/CD pipelines to trigger and execute playbooks. Services and workflows can be scheduled to start at a later time, or run periodically with CRON. Services and workflows can additionally be triggered by external events such as a REST call or Syslog message etc.
Tools like Ansible, StackStorm, Saltstack, Rundeck, itential, Jenkins are highly applicable here.
7) VERSION (SOURCE) CONTROL SYSTEMS
A version control system is a powerful tool that helps you share files, track changes, and manage changes to those files. A popular tool in this space is Git. This is a distributed version control tool that supports distributed non-linear workflows by providing data assurance for developing quality software. It also allows for collaboration in the development of scripts, fullstack software or applications!
Some of the benefits of version control in Network Engineering include:
- Python scripts for network devices can be hosted in version control systems so that changes to those scripts can be easily tracked
- You can use version control to host network device configurations, this helps your team to know the state of your network device at any point in time, also, changes made to the configuration can be highlighted and tracked.
8) VERIFICATION, TESTING AND VALIDATION SYSTEMS:.
Today, networking operation teams are still mainly using ping, traceroute, and human verification for network validation and testing. These tasks are not only laborious but also anxiety-inducing, since a single mistake can bring down the network or open a gaping security hole.
When architecting a network automation solution, we need to start treating the network infrastructure as software. The most important part of writing quality software is testing. Writing unit tests provide assurance that the changes you’re making aren’t going to break anything in your software, scripts and network environment at large.
In our example, the network is the application, and unit tests need to be written to verify our application has valid configurations before each change is implemented, but also integration tests are needed to ensure our application is operating as expected after each change.
Platforms such as Forward Networks/Veriflow, Batfish, Vagrant, GNS3, Eve-NG, and Tesuto are very applicable here.
9) SOFTWARE DEVELOPMENT SYSTEMS:
Software development is the process of conceiving, specifying, designing, programming, documenting, testing, and bug fixing involved in creating and maintaining applications, frameworks, or other software components.
Choosing a programming language to use for developing your automation solutions depends on a lot of things, for instance, the current expertise in your team, community support and the ease of use. With that being said, python has become the principle language for network automation, so it makes sense to focus on it. Go is a language that is also gaining a lot of traction these days too.
Second, you also need to ensure that the quality of code you write is up to the mark. You can do this through automated testing. This helps pinpoint and eliminate bugs that are challenging to diagnose. With automated testing, it is then a step to continuous integration and continuous delivery. CI/CD runs comprehensive tests whenever new code or network configurations are checked into the software code repository. If all tests are passed, the updated code is ready for deployment, either manually or automatically, as determined by the organization.
Another important factor to consider is software packaging. When you get to a more mature and advanced stage in your network automation journey; where you’re automating at scale and dealing with mission critical systems. How you package and deploy your automation solutions becomes critical. Preferably, use containers with deployment on Kubernetes. Containers simplify and avoid many issues that come with managing dependencies.
References
Iyengar, A. (2021). An overview of network automation and highlights how automation is facilitated in the last mile by edge computing. IBM. https://www.ibm.org/cloud/automation-at-the-edge
Majumdar, S., Trivisonno, R., & Carle, G. (2022, May). Scalability of Distributed Intelligence Architecture for 6G Network Automation. In ICC 2022-IEEE International Conference on Communications (pp. 2321-2326). IEEE. https://doi.org/10.1109/ICC45855.2022.9838791
No Comments